Modern Microprocessors in 90-minute guide 筆記
圖與表格皆來自原文
More Than Just Megahertz
首先要釐清的觀念是 — 時脈並不等同於處理器效能。
可以看下表的比較:
| SPECint95 | SPECfp95 | ||
|---|---|---|---|
| 195 MHz | MIPS R10000 | 11.0 | 17.0 |
| 400 MHz | Alpha 21164 | 12.3 | 17.2 |
| 300 MHz | UltraSPARC | 12.1 | 15.5 |
| 300 MHz | Pentium II | 11.6 | 8.8 |
| 300 MHz | PowerPC G3 | 14.8 | 11.4 |
| 135 MHz | POWER2 | 6.2 | 17.6 |
除了時脈外,一個時脈週期能夠執行的指令數(Instruction Per Cycle, IPC)也是決定效能的關鍵因素。
因此就有了 … Pipelining & Instruction-Level Parallelism
Pipelining & Instruction-Level Parallelism
指令是如何被執行的?
- 抓取指令
- 解碼
- 執行
- 將結果寫入
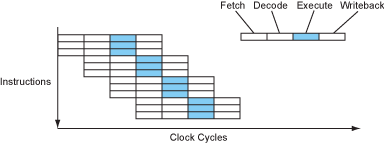
因此最簡單的處理器可以想像成每個指令 4 個時脈週期(CPI = 4),如下圖:

現代處理器會將不同階段重疊成一條管線(pipeline),就像工廠的組裝線(組裝完第一部分交給第二部分時,第一部分的負責人可以進行第二項產品的第一部分組裝),在此設計下,處理器就變成每個指令 1 個時脈週期(CPI = 1,將指令數增加可以發現 CPI 越來越接近 1)如下圖:

管線(pipeline)的各個階段會由 latch [1] 來切開,並負責傳遞各個階段的結果,而 latch 則是由 clock 來控制的。

由於指令執行完後的結果可能是下個指令要用到的,與其被塞著等結果寫入,不如加個旁通管(bypasses)。

上面的解說圖看似簡單,以執行階段來說,裡面應是由各種不同的邏輯電路所組成,像是分支(branch)、整數運算(int)等等。
早期的精簡指令集計算(Reduced Instruction Set Computing, RISC) 處理器較容易做到管線的設計(像是 IBM’s 801, MIPS R2000, original SPARC)。在同一時代,主流處理器(80386, 68030, VAX CISC)基本上都是循序執行的,也因此即便時脈較低,運作的速度仍會比時脈高的還要快。
[1]: 一種儲存資料的電路,詳情可見最下方補充。
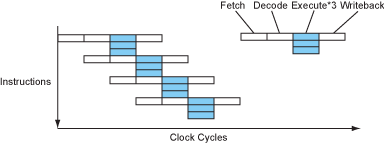
Deeper Pipelines - Superpipelining
clock speed 取決於最長的階段(stage)[1],將最長的拆細,變成多個較小的階段,如此一來處理器可以擁有更快的 clock speed。
理想上,stage 變多 → 一個指令所需的 clocks 數變高,但是 clock speed 提升了,每秒可以擁有更多的 clocks,而 CPI 仍然是 1 → 整體效能提升。
[1]: 可參考補充的 sequential circuits 中的 synchronous 介紹,裡面提到 clock 的間隔必須足夠長讓邏輯電路能夠跑完,在這裡也是差不多意思。
Multiple Issue - Superscalar
由於執行階段(execute stage)內部是由多個不同的功能元件所組成,每個所負責的任務不同,因此具有同時執行多個指令的可能性。然而想要做到這點就必須強化抓取與解碼的功能,才可以同時處理多個指令並派送到適當的功能元件去執行。下圖為示意圖:
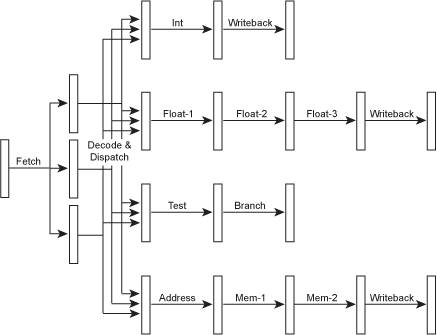
不同的功能元件會有獨自的管線,也就代表著擁有不同的階段數。這樣的設計是為了讓簡單的指令可以執行的更快,而非跟著複雜的指令走同一條管線。一般在提到處理器的管線深度時會以 integer 指令來做標準。前面提到的旁通管(bypasses)在這樣的設計下也是存在的,並且是能夠跨管線的。
在這樣的設計下,指令流大概如下圖:
- CPI = 0.33
- IPC = 3 = ILP (Instruction-Level Parallelism)
- 能夠同時處理的指令數通常被稱作處理器的 issue width
- 通常功能元件會比 issue width 還要高,畢竟每次需要處理的指令不同,不可能那麼剛好各使用其中一個元件
現今處理器多半都是 superpipelined-superscalar。
Explicit Parallelism - VLIW
VLIW - Very Long Instruction Word
- 一個指令包含多個小指令
- 指令長度非常長
- 可以減少 fetch, decode 的邏輯複雜度
指令流大概如下圖:
多數 VLIW 的設計都不具有互鎖(interlocked)的特性,也就是不會檢查指令間的相依性,這導致一個問題:當 cache miss 時就必須暫停(stall)整個處理器。(其他處理器能夠去處理沒有相依性的指令)
Instruction Dependencies & Latencies
Pipeline 跟 multiple issue (issue width) 的數量是有其限制的,並非可以無限加大加深。看看下列例子:
a = b * c;
d = a + 1;
像上面這樣,指令間基本上都存在著相依性,在這樣的情況 multiple issue 是做不到的,至於 pipeline 則是要看前面指令的複雜性,若是加法,可以透過旁通管(bypass)來將結果餵給下一條指令;若是較複雜的乘法(需要較多 cycle 來完成結果)就無法在一個 cycle(decode → execute)之內把資料準備好。
Compiler view: 指令從進入執行階段到產出結果並能夠被使用的這段期間所需的 cycles 數量被稱作指令的延遲(Latency)。
載入記憶體內容的延遲是不好處理的,因為它們通常發生在整段程式的前期,也因此無法塞入一些有意義的指令去有效利用資源,同時它們也不好預測(跟 cache hit / miss 有關)。
Branches & Branch Prediction
根據統計,每 6 個指令就會遇到 1 個分支,因此分支的預測是十分重要的議題。
程式碼片段:
if (a > 7) {
b = c;
} else {
b = d;
}
經過編譯後:
cmp a, 7 ; a > 7 ?
ble L1
mov c, b ; b = c
br L2
L1: mov d, b ; b = d
L2: ...
考慮上面的情況,在 line 2 的分支判斷結果確定前,處理器就必須抓取並解碼下一段指令了(有 pipeline)。處理器會作出預測,並執行預測到的指令,但是會等到結果確定才會去做寫入的動作。
預測的方法有兩種:
- Static branch prediction
- 交由編譯器來做標記
- loop 類的很簡單,但是其他就比較難
- On-chip branch prediction table
- 在執行階段做預測
- 理論上是用 1-bit 來做標記,紀錄上次的狀態
- 實務上會用 2-bit 來做標記,來避免一些邊際測資(edge case)破壞整體的預測走向
以 Pentium Pro/II/III 為例,再聰明的預測也頂多達到 90% 的準確率,一旦預測失敗便需要承擔 mispredict penalty(取消目前指令,並執行正確指令),大概是 30% 左右的效能損失。
為了提高預測的準確率,有許多方法出現:
- Two-level adaptive predictor
- 並非單純紀錄分支方向,而是會紀錄歷史脈絡(context),也就是什麼樣的過去走向會導致這次的走向(這邊的脈絡是指同一條分支指令的脈絡,而非跟其他分支之間的關聯)
- 通常會設定紀錄 n 次歷史記錄,也就會有 2^n 種分支歷史狀況
- 能夠預測在 n 次內出現的所有的重複情況的模式
- Gshare / Gselect predictor
- 保有全局分支記錄,也就是全部分支共用同一份記錄
- 能夠辨識不同分支之間的關聯性
- 預測容易被其他分支的結果給稀釋
現代多數處理器都會實做幾種分支預測器,並在不同情況下使用不同的分支預測器。
Eliminate Branches with Prediction
再借用上一章節的例子說明:
cmp a, 7 ; a > 7 ?
ble L1
mov c, b ; b = c
br L2
L1: mov d, b ; b = d
L2: ...
試著將 mov 指令改造一下,讓它能夠在特定條件下再執行:
cmp a, 7 ; a > 7?
mov c, b ; b = c
cmovle d, b ; if le, then b = d
cmovle 代表著 “conditional move if less than of equal”,它基本上就是照常執行,但是只有在條件符合的情況下才會做寫入,被稱為 “predicated instruction”(在這 predicate 指的是一個 true/false test,語彙力不足,不知怎翻 QQ)。
在這個新的指令的幫助下,上面的指令組成變得更好了,除了少了兩個花費很高的分支指令外,平行度也增加了(line 1, 2 可以同時進行了),最重要的是排除掉了 mispredict penalty 發生的可能性。
然而上面的情況是較為簡單的,當 if / else 的區塊擁有更多指令需要執行的時候,是否要使用這樣的指令是很難去取捨並決定的。
Instruction Scheduling, Register Renaming & OOO
分支或是長延遲的指令會在管線中塞入泡泡(bubbles,像是 nop)來暫緩後面的指令執行,若能夠對於指令的順序做規劃,讓較後面不會被影響到的指令先拉到前面,跟著上述兩類的指令一同執行也許會更有效率?!
有兩種方法:
- 動態:在執行時期的硬體端做重新排序
- 處理器的 dispatch 邏輯必須去看多組的指令組,來盡可能地做到最佳的指派任務
- 稱為 out-of-order execution(OOO / OoO / OOE)
- 必須處理好指令間的相依性,避免 hazard 的發生
- 利用 register renaming
- 邏輯設計複雜化、功耗高
- 靜態:在編譯時期由編譯器來最佳化指令的順序
- 稱為 static / compile-time instruction scheduling
- 能夠比硬體端看得更遠、更全面
現今多數高效能的處理器都具有 OOO 設計。
The Brainiac Debate
基本上是在講古,也就是前面提到的處理器設計問題,兩大方向(brainiac vs speed-demon)之間的拉扯(trade-off)歷史,並在最後放了圖表來綜觀歷史上各家處理器廠商開發的走向(詳情見原文)。
The Power Wall & The ILP Wall
Power Wall
- 時脈速度的提升伴隨著熱的提升
- 現有的散熱技術有其限制
- 即便電路能夠以更快的速度運行,但是散熱技術做不到的話就沒辦法如此設計,也就是 “Power Wall”
ILP Wall
- 載入延遲
- 快取失效(cache miss)
- 分支
- 指令間的相依性
- 由於上述四點,ILP 有其極限,也就是 “ILP Wall”
What About x86?
儘管 x86 指令集相當複雜,它至今仍能保有競爭力的原因?
在現今 x86 處理器中,會將 x86 指令轉換成類似 RISC 的微指令再進行處理,這些類 RISC 的微指令稱為 μops(唸作 “micro-ops”)。這樣的轉換使得 x86 指令也能夠以快速、RISC-style register-renaming OOO superscalar 核心上跑。
基本結構大概如下:
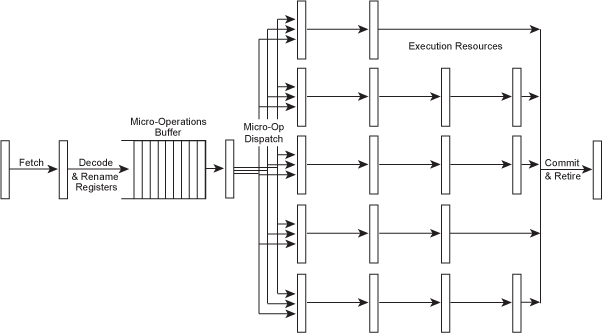
- decoupled architecture
- 用以實現高效計算
- 將「記憶體存取」與「執行部分」分開來平行處理,方法是實做一個資料緩衝區(data buffer)
- 詳情請見
某些 x86 處理器甚至有 “L0 cache” 來紀錄已經轉換好的 μops 避免之後重複轉換,這也是為什麼某些處理器在描述 stages 會有像是 14/19 stages 這樣的情況,14 代表的是 cache hit,19 則是 cache miss 的情況。
Threads - SMT, Hyper-Threading & Multi-Core
如同前面提到的,多數程式並不具備良好的平行度設計,因此設計 superscalar 的處理器並透過 ILP 所能夠提升的效能是很有限的。
除了同一支程式內的指令,其他程式或是其他緒程(thread)的指令也可以拿來填充 bubbles 用,Simultaneous Multi-Threading (SMT) 的處理器設計也就為了 thread-level parallelism 而生。與 multi-processor 不同的是,SMT 是在同一個處理器上執行多個緒程,而 multi-processor 雖然也能夠同時處理多個緒程但是在單一個處理器上只有一個緒程在跑(多核心的也是,單一核心只有一個緒程)。
以硬體層面來說,設計成 SMT 的樣子並不會需要太多硬體空間,它基本上只需要多一份空間來紀錄程式計數器(program counter)、暫存器、記憶體空間對應等等關於緒程執行狀態的資訊,其他較為複雜的部分像是解碼器、功能元件、快取等等皆能夠共用。
SMT 處理器的指令流大概如下圖:
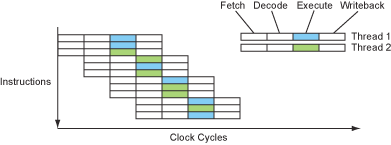
即便上面關於 SMT 的描述看起來很美好,但實際情況並非如此。以上面描述的情況(可以用其他程式或是其他緒程來填補 bubbles)來說,現實世界多數的情況並非適合讓 SMT 發揮,像是同時有好幾支程式正在活躍地執行的情況是很少出現的。
在眾多擁有高度平行性的應用中(資料庫系統、影像處理、3D 圖像渲染、科學運算),多數並沒有以多緒程的方式來進行撰寫,且多半的瓶頸都是記憶體頻寬並非是處理器效能。
此外由於功能元件部分是共用的,若多個緒程都在做差不多的事情的話(需要相同的功能元件),那即便是 SMT 的設計仍舊必須無法做到有效利用。SMT 適合的情況是平常以 memory latency 為瓶頸的應用,也因此讓 SMT 的商業宣傳十分尷尬,一款 SMT 處理器某些時候能夠快得像是擁有「兩個」處理器在同時工作,有時候就像是「兩個」很爛的處理器。
More Cores or Wider Cores?
multiple-issue 的分配邏輯電路是相當複雜的,基本上是以 issue width 的次方倍(n 個候選指令要互相比較)在複雜化的,同時,為了服務多個同步存取需要多埠暫存器以及快取,而這造成電路的拉長也因此降低了時脈速度,因此核心 issue 數並非越多越好,若拿所需要的整體空間去換成較弱但多個核心,表現不一定會比較差。
到底哪一種好?端看程式的用途。
- 簡單但多個核心
- 多個活躍但受到記憶體存取延遲所影響的緒程
- 複雜但是較少核心
- 大部分應用都適用
兩者之間佔比的拉扯仍舊有很多空間能夠做嘗試(像是非對稱的設計 - 一個複雜 + 多個簡單的)。
Data Parallelism - SIMD Vector Instructions
除了 instruction-level parallelism 與 thread-level parallelism 外,還有一個 data-level parallelism 能夠利用,又稱為 SIMD parallelism (Single Instruction Multiple Data)、vector processing。
在像是媒體處理相關的應用上,常常需要對一整組的資料執行相同的指令,像是影像處理中對於像素的呈現:
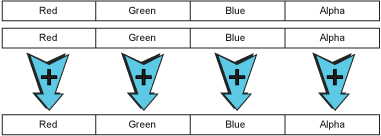
SIMD 指令在適當的情境下可以帶來很大的加速,但要透過編譯器來自動使用 SIMD 指令是相當難的,因為一般撰寫方式傾向序列化,這讓編譯器很難去判斷兩個指令是相互獨立且可以平行運作的。要好好利用必須得重新實做相關部分的程式碼。好消息是,多數常用的函式庫近年來都有在進行改寫。
Memory & The Memory Wall
為了從記憶體上載入資料來做計算花費許多時間,然而要建立一個高速的記憶體系統是很困難的:
- 記憶格(memory cell)的充放電需要時間
- 跟記憶體之間的訊號傳遞需要時間
必須在既有的物理條件下繞道而行。
現代處理器能做到的是將記憶體控制器整合進處理器晶片,加快了原先較慢 cycles(原先與晶片分開需要 2 bus cycles 來做資料傳輸)。
處理器與記憶體之間的運作速度差距稱作 memory wall。
Caches & The Memory Hierarchy
現代處理器利用快取來解決上一節提到的 memory wall,快取座落在處理器晶片上或附近。
一般來說會有一個主要的快取 - “level 1 (L1)” 快取(一般會將資料與指令的快取分開,分別為 D-cache 與 I-cache)放在處理器晶片上,大小為 8-64k;再遠一點但仍在晶片上會有另一個 “level-2 (L2)” 快取,大小為 N kb ~ N mb;有些甚至會有 L3, L4 等等。on-chip 快取、off-chip external 快取(E-cache)以及 RAM 三者組成記憶體階層(memory hierarchy)。
標準的現代記憶體階層長得大概如下:
| Level | Size | Latency | Physical Location |
|---|---|---|---|
| L1 cache | 32 KB | 4 cycles | inside each core |
| L2 cache | 256 KB | 12 cycles | beside each core |
| L3 cache | 6 MB | ~21 cycles | shared between all cores |
| L4 E-cache | 128 MB | ~58 cycles | separate eDRAM chip |
| RAM | 4+ GB | ~117 cycles | SDRAM DIMMs on motherboard |
| Swap | 100+ GB | 10,000+ cycles | hard disk or SSD |
現代 L1 快取的 hit rates 大概可以達到約 90%,這是因為多數程式都擁有時間與空間上的 locality。同時,為了好好利用空間上的 locality,在從 RAM 上複製資料到快取時,是複製從要求的位址開始好幾個位元組上來,稱為 cache line。
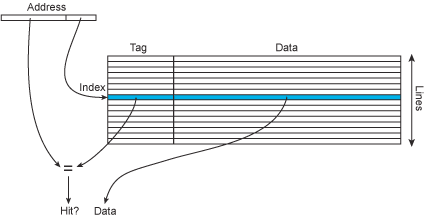
- Address 被拆成兩部分
- lower part(右邊)作為索引,來定位快取資料的進入點
- higher part(左邊)與 tag 做比對,來判斷是否是想要的區塊,因為快取用 lower bit 來做索引,這樣一來不同位址但是相同 lower bit 的會被放到同一個快取的欄位,tag 可以用來判斷位址是否正確
快取的詳細運作可參考:淺談 memory cache
快取的查找有兩個方式:
- virtual address
- 可能會有不同程式、相同虛擬位址、不同物理位址的情況,這樣一來每次做 context switch 時就必須 flush
- physical address
- 會有額外的虛擬轉物理的操作延遲
現今常用的技巧是混合法,使用虛擬來查找,但是 tag 是用物理位址。在用虛擬位址來定位快取欄位時,高位位址可以同時進行虛擬與物理間的對應轉換(TLB lookup),這種方式稱為 virtually-indexed physically-tagged cache。
Cache Conflicts & Associativity
為了要能夠在快取上快速存取想要的資料,最簡單的方法是,使用簡單的對應(mapping)機制,像是前面的單純使用低位位元來定位(稱為 direct-mapped cache),且只保留「最近」使用到的資料。然而,這在特定情況下會造成很大的問題,像是若程式需要不斷的存取兩個位址,但是那兩個位址都對應到快取上的同一個欄位,這樣的問題稱之為 cache conflict。在這樣的情況下,即便程式運行具備時間上的 locality,處理器仍舊只能不斷的去存取 main memory,使得快取顯得毫無用處。
為了處理這樣的問題提出了 N-way set-associative cache,基本上就是額外開 N - 1 張表來當作快取,來提高對於衝突的容忍度。然而,隨著 N 的提高,雖然看起來越聰明但是邏輯電路複雜度也會隨之提高(像是要需要更新的使用時間戳記會變多),一般來說以 4-way 最為理想。
Memory Bandwidth vs Latency
頻寬跟延遲的差異:
- 以高速公路為例
- 頻寬代表的是高速公路上的車道數量有多少
- 延遲代表的是這條高速公路(從 A → B)有多遠
這兩者之間的 trade-off 也是根據不同的應用情形而改變。以 pointer-chasing 程式為例(編譯器或是資料庫系統),適合的是延遲較低的設計;以簡單且線性存取的程式為例(影像處理),適合的是頻寬較大的設計。
近年來對於記憶體存取延遲的改進是透過 synchronously clocked DRAM (SDRAM) 的設計來做到的,設計上主要有兩個特點:
- 與中央處理器計時同步
- 對於資料的讀寫具有預測性,可以精準的傳遞資料,不需要讓處理器額外等待記憶體的週期跟上
- 管線的使用
- 以往每個對於 main memory 的存取都要一個個來,有了管線的設計,在前一個存取的資料還沒回來前就能夠送出下一道存取的指令
補充
Synchronous Sequential Logic
ref: Digital Design With An Introduction to the Verilog HDL Fifth Edition
Combinational v.s. Sequential
- Combinational Logic
- 輸出僅依據輸入,沒有記憶的概念(在這記憶指的是依賴過去的值)
- Sequential Logic
- 可以儲存、保留過去的值,並在後面用上
Sequential Circuits

- 儲存在記憶元件上的資訊定義著 sequential circuit 的狀態
- 由輸入、輸出、內部狀態的時間序列所規定(定義)的
- 有兩種類別,由訊號的時機來區分:
- synchronous
- 被 clock 所支配
- 狀態是可預測的
- 同時也被 clock 所限制,clock 的間隔必須足夠長,讓邏輯電路能夠完全做完
- asynchronous
- 由輸入支配
- 僅被邏輯電路的傳播延遲所限制
- 有 race condition 的風險
- 難以設計與實做,因此不常見
- synchronous
Storage Elements: Latches
- 儲存元件有很種,主要以下列要素做區分:
- 輸入的數量
- 哪個輸入影響了狀態的值
- 是由訊號的值來驅動的。(flip-flop 由訊號的變化來驅動)
- SR Latch
- 由兩個 NOR / NAND gates 所組成
- 兩個輸入:S, R 分別代表設定(set)與重設(reset)
- 輸出有 Q, Q’,(1, 0) 時稱作 set state,(0, 1) 稱作 reset state
- 在 NOR gate (NAND gate) 的設計下 S, R 不可同時為 1 (0)
- 一般情況下兩個輸入都會維持 0 (1),只有當狀態需要改變時才會有 1 (0) 的出現
- 一旦設定好狀態需要馬上降回 0 (1)
- NAND gates 版本可被稱為 S’R’ latch
- 通常會加入一個額外的輸入來決定說什麼時候要依據 S, R 來改變訊號
- 小記:
- 與室友討論後,目前心得是不需要去思考迴路的初始值(也就是 Q, Q’),只要初始值符合規定(互為對方的補數),電路到穩定態時會是符合真值表的
- D Latch
- 為避免 SR Latch 而產生
- 可以想像為 S 就是 D,而 R 是 D’
- 因其設計而多作為內部儲存元素